OpenMetadata production stories from OpenAI, Yelp, Rakuten & more — Learn More about Collate Summit '26 🚀
Community Case Study
Aspire Enables Financial Freedom with Trusted Data Context
1700+
tables centrally documented and governed in OpenMetadata
6100+
data quality tests standardized to build trust
50+
active users collaborating on shared data context

Aspire operates a fast-growing, multi-product finance platform supporting modern businesses across Asia, where reliable data is essential for reporting and decision-making at scale. As Aspire expanded rapidly across the region, its data ecosystem outpaced the team’s ability to manage metadata manually. Employees struggled to understand what data existed, how it was defined, who owned it, and whether it could be trusted. By implementing OpenMetadata — internally branded as Bifrost — Aspire established a centralized, business-friendly system of record for metadata, enabling teams to confidently discover and understand data across the organization.
Industry
Fintech / Financial Services
Technologies
Amazon MWAA, dbt, Tableau, OpenMetadata
"OpenMetadata helped us turn tribal knowledge into shared knowledge, making it easy for team members to understand and use data as the organization scales."
Vinol Joy D'souza
Head of Data at Aspire
Manual workflows and data silos created blind spots in metadata trust
As Aspire scaled its platform and teams, metadata management relied heavily on Google Sheets and ad hoc documentation. What initially worked for a small set of assets quickly became unsustainable. Documentation fell out of sync with reality, ownership was unclear, and teams increasingly relied on tribal knowledge to answer basic questions about data.
According to Vinol Joy D’souza, Head of Data at Aspire, “Due to our previous data architecture, our teams lacked a consistent source of truth for understanding what data existed, how it was defined, and whether it could be trusted.” These gaps created friction across analytics and engineering workflows and slowed decision-making:
Manual, fragmented metadata management
Metadata lived in Google Sheets and siloed documentation that quickly became outdated and difficult to maintain as data assets and stakeholders scaled.
Lack of end-to-end data context
Teams lacked a unified view of their data and related context, making it hard to understand how data was produced or used.
Limited visibility into data quality and impact
Without data lineage, impact analysis or reliable quality signals, root cause analysis took longer and teams struggled to assess downstream risk when changes occurred.
Reactive QA and incident management
Ingestion issues were discovered manually via Airflow checks.
Eroding trust and increased dependency on data teams
Inconsistent metadata and unclear ownership reduced confidence in analytics and forced stakeholders to rely on data engineers for basic clarification.
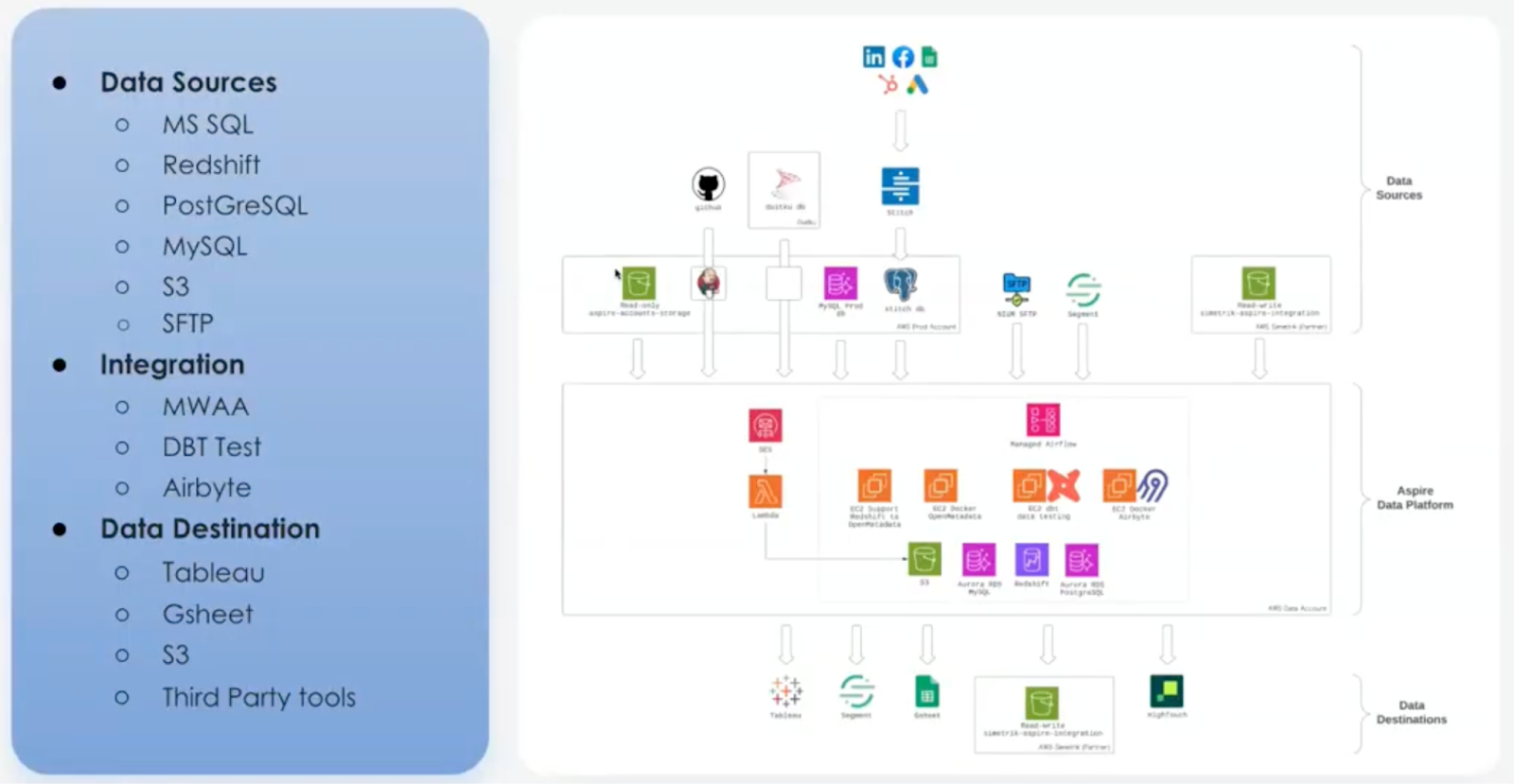
A unified system of record for data discovery and governance
Aspire needed a centralized metadata foundation that could replace manual documentation, scale with the business, and make data self-serve for both technical and non-technical users. The team implemented OpenMetadata — branding it internally as Bifrost — to serve as the authoritative system of record for metadata across the data stack.
OpenMetadata unified context across all of Aspire’s data assets across tables, dashboards, and pipelines—allowing teams to quickly and securely find what they needed while understanding dependencies and ownership. As Aspire continued to grow, the platform helped convert tribal knowledge into shared, reusable context, reducing the reliance on long-tenured employees and freeing engineering time for higher value work. Key capabilities included:

Self-serve data discovery
Search across tables, dashboards, pipelines, and business terms enables teams to find data and confirm ownership without relying on engineers.
Richer context through lineage and classification
Lineage mapping, sensitivity tagging, and tiering clarify data importance, usage, and downstream dependencies.
Standardized, visible data quality signals
A structured data quality framework surfaces test results directly alongside analytics and reporting.
Actionable observability workflows
Quality monitoring is paired with investigation and resolution workflows, ensuring issues are owned and addressed.
Consistent governance without central bottlenecks
Apply controls consistently while allowing teams to retain autonomy.
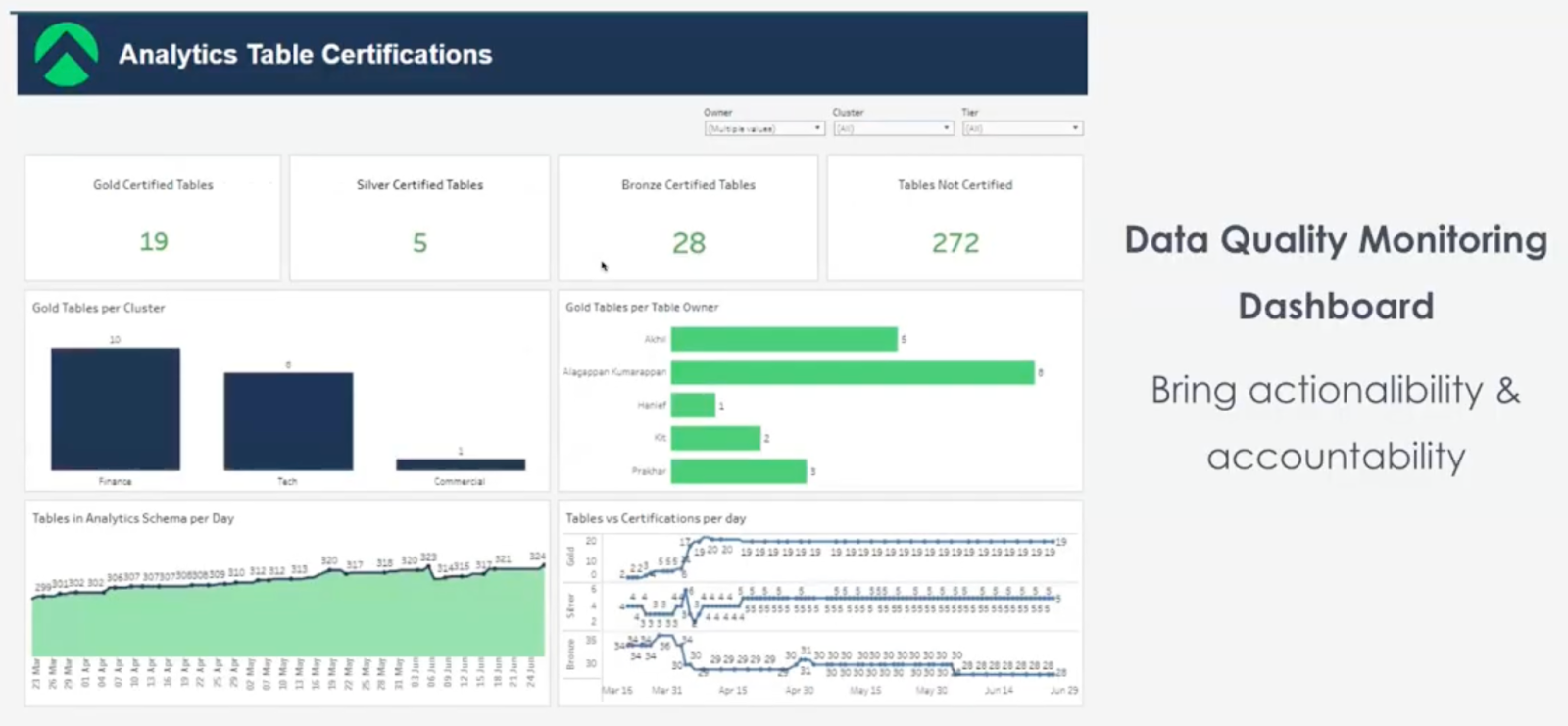
Stronger data trust, faster understanding at scale
By implementing OpenMetadata as a centralized metadata foundation for Bifrost, Aspire shifted from reactive data firefighting to a more proactive approach to data discovery, quality, and governance. What had once depended on manual documentation and institutional knowledge evolved into a shared system that scaled with the organization, supporting both data teams and business stakeholders alike.
“With Bifrost in place, we’ve created a clearer, more consistent data experience for our teams across the board,” said D’souza. That clarity translated into measurable improvements across data quality, adoption, and operational efficiency.
Metadata coverage at scale
Centralized documentation and governance for 1,700+ tables, delivering consistent visibility across core data assets.
Standardized data quality practices
With 6,100+ data quality tests tracked in OpenMetadata, teams established shared standards and clearer signals around data reliability.
Improved onboarding and self-serve usage
Lineage, tagging, and tiering reduced reliance on tribal knowledge and accelerated ramp-up for new team members.
Broader adoption across teams
More than 50 users actively engage with OpenMetadata, which extends metadata ownership beyond the core data team.
Greater confidence in analytics
Quality and context are surfaced alongside dashboards, reducing uncertainty and improving trust in reporting.
Centralized governance without bottlenecks
Centralized definitions and classifications improved coordination while preserving team-level ownership.
